When introducing myself to someone professionally, I usually start with the normal “Hi, my name is …” that is boiler-plated on nametags the world over. Getting past that initial point, if the person is so inclined, they ask that always fun lead off question “So, what do you?” For me, I always respond with “I am an SDET”1, to which anyone not in the software industry replies back with “Um.... What is that?”
Spewing out “It means I am a Software Development Engineer in Test.”, I wait for the response that most people use: “Oh, so you are a tester.” Often with gritted teeth, I try and explain that testing is only a small part of what I do. If I think they are still listening, I given them my quick elevator pitch that emphasizes that I focus on helping to produce good quality software by helping to increase the quality of the teams, the projects, and the processes that I am tasked to assist with.
Approximately 60-70% the time I win people over with the elevator pitch, and a pleasant conversation continues. The next 20-30% of the time, usually with people not in the software field, I get blank stares and they fixate on the “test” in the title rather than the “quality” in my description. The remaining people are usually Software Development Engineers or SDEs2 that for one reason or another, start to tune out.
For the percentage of people that I win over, they seem to understand that I focus on quality, but the follow up question is almost always: “What does quality software mean to you?”
Where do we start?¶
For me, I almost always start at the beginning with requirements. Whether they are spoken or written down, each project has a set of requirements. It could be the requirements are to “explore my ability to use X” or “fix the X in the Y project” or “create a project that can help me X”, but every project has requirements.
In the software development industry, requirements are often presented to teams that are hard to deal with or are left to the developers to write themselves. This practice is so prolific that Scott Adam’s Dilbert site has pages and pages of instance where requirements are talked about. One example is when a manager talks to their team and informs them that some process needs to be faster by 5%. Do they have enough information from that manager to understand the context of the requirement? Do they expect that increase by a specific time to meet their own goals? What does that requirement look like? How do they know when they have achieved it? Is it achievable? If it is achievable, how do they measure progress towards that goal? These are some of the core questions that I believe need answering.
As those questions are at the front of my mind, when someone asks me how I define software quality, the first thing I immediately think back to is a course that I once took on setting S.M.A.R.T. requirements. In that class, the main focus was on taking unrefined requirements and curating them to a point where they could be more readily be acted upon. The instructor made a very good argument that each requirement must be Specific, Measurable, Assignable, Realistic, and Time-Related.
When it comes to software quality, I believe those same questions needs to be asked with regards to any of the requirements teams put on their software. But to ask those questions properly, we need to have some context in which to ask those questions. To establish that context, it is helpful to have some guidelines to provide a framework for the requirements.
Establishing Some Guidelines: The Four Pillars¶
A good general article for anyone interested in software quality is the Wikipedia article on Software Quality. In fact, when asked by people where to get started in the software quality area, I often refer them to this article solely because of the excellent diagram in the Measurements section on the right side of the page.3
The diagram in the Measurements section correlates very closely to what I believe are the four pillars of software quality: Reliability, Maintainability, Efficiency, and Security. The diagram then shows how their pillars relate to other attributes: Application Architecture Standards, Coding Practices, Complexity, Documentation, Portability, and Technical/Functional Volumes. From there, it provides more lists of how to break things down, with many references to other articles. In short, it is a great place to start from.
Measuring Software Quality¶
Before proceeding to talk about the pillars themselves, I feel strongly that we need to discuss the categories that I use for measuring the metrics talked about in the Wikipedia article. My intention is that by talking about the metrics before discussing each of the pillars, you can start building a mental model of how to apply them to your projects as you are reading about them. From my point of view, making that mental transition from something abstract that you read about to something concrete that applies to your work is essential to serious forward momentum on software quality.
These metrics typically fall into two categories: seldom violated metrics and positive momentum metrics.
The seldom violated metrics category contains rules that define rules that are pivotal to the quality of your project. Each rule are a combination of a given metric and a maximum or minimum weighed against that metric. As a guideline, teams should only ignore these rules on a case by case basis after providing a reason that is good, defensible, and documented. Examples of such metrics are Service Level Agreements (SLAs), Static Code Analysis (SCA) results, and Test Failure Rates. Examples of rules are “the TP99 for the X API is Y millisecond” or “all PMD warnings (Java SCA tool) must be following with a minimal of suppressions”.
Furthermore, to make these rules useful and to keep your team honest, your team needs to publish the selected metrics, with a description of what the metrics are, how your team measures those metrics, and why your team is measuring them.
The positive momentum metrics category is usually reserved for metrics that are being introduced to an already existing project. When introducing software quality metrics into an already existing project, it is not realistic to expect those metrics to be adhered to in an instant. It is more realistic to expect positive momentum towards the goal until the point when your team achieves it, at which point is moves to the desired seldom violated metrics category. As such, a measure of the momentum of these metrics is used, and is hopefully in a positive direction. Similar to the previous category, your team should publish information about the selected metrics, with the added information on when your team feels they will translate it from the positive momentum category to the seldom violated category.
Being consistent on these chosen metrics is very important. While dropping a metric looks better on any reporting in the short term, it usually negatively impacts the software quality, perhaps in a way that is not obvious until later. Adding a new metric will show lower the measured quality in the short term, but increases the measured quality in the long term. Your team can negate the short term impact by paying the immediate cost of making the new metric a seldom violated metric, but that has to be weighed against the other priorities for your project. As with everything, it is a balancing act that needs to be negotiated with your team.
Exploring The Four Pillars¶
Having established that S.M.A.R.T. requirements and the two categories for metrics from the previous sections are useful in measuring software quality, the focus of the article can return to the guidelines: the four pillars. Each one of these pillars will look at your software project from a different angle, with the goal of providing a set of data points to formulate a coherent measurement of software quality for that project.
In the following sections, I strive to describe each of the four pillars, providing a jumping off point to another article that describes that pillar in a more comprehensive manner. I firmly believe that by providing metrics for each pillar that are specific to your project, with each of those metrics properly categorized into the two measurement categories documented above, that your team will take a decent step forward in clearly defining software quality for your project.
Reliability¶
The essence of this pillar can be broken down into two questions:
- Does the software do the task that it is supposed to do?
- Does the software execute that task in a consistent manner?
Reliability is one of the areas in which “pure” testing shines. A lot of the tests that SDEs, SDETs, and testers are asked to write specifically verify if a given object does what it is supposed to do. Unit tests determine whether an individual software unit, such as a class, performs they way it is supposed to. Functional tests or integration tests take that a step higher, determining whether a group of related software units do what they are supposed to do. Another step higher are the scenario tests, which determine whether the software project, as a whole, responds properly to various use cases or scenarios that are considered critical to its operation. Finally, end-to-end tests or acceptance tests determine whether or not a group of projects respond properly from an end user’s perspective.
This pattern is so widely used, any search for test pyramid, will find many variations of the same theme. Different articles on the subject will stress different points about the pyramid, but they will all generally look like this:
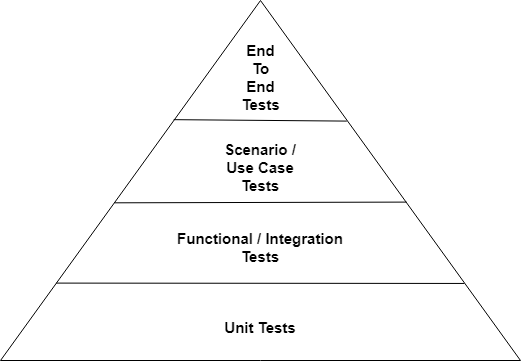
This pyramid, or other similar pyramids, are interpreted by authors to indicate a specific things about the tests, to highlight the position of their article. Some of these interpretations are:
- An article on test volume will typically stress that ~70-80% of the tests should be at the unit test level, ~10-15% at the functional test level, ~5-10% at the scenario level, and ~1-3% at the end-to-end level.
- An article on test frequency will typically stress that tests near the bottom of the pyramid should complete within 60 seconds and be executed every time the source code is checked in. Tests near the top of the pyramid may take minutes or hours and should be executed once a week.
- An article on test fragility will typically stress that tests near the bottom of the pyramid are closer to their components, the expectation is that they will not fail. Tests near the top of the pyramid require more orchestration between projects and teams, and therefore, are more likely to failure do to environmental or other reasons.
While all of these interpretations have merit, the critical point for me is the issue of
boiling down that information to a small number of bite sized observations that can be easily
measured and communicated. In the upcoming article Software Quality: Reliability, I will
delve more into breaking the Reliability pillar into S.M.A.R.T. requirements and I provide
suggestions on how it can be measured.
Maintainability¶
The essence of this pillar can be broken down into one question:
- If you are asked to change the software to fix a bug or introduce a new feature, how easy is it to change the software, how many surprises do you expect to encounter, and how confident will you be about the change afterwards?
The best, and most comedic, form of asking this question is captured by this cartoon from OSNews:

Maintainability is a single pillar that encompasses the most diverse types of processes and measurements of any of the pillars. The reason for this is that maintainability is often a word that is used without a lot of provided context. For me, a good way to think about maintainability is that it is the cleanliness of your project. Different people will have different experiences, and after asking different people about how “clean” the project is, the collected answers will almost certainly by different.
Try this in your office with your colleagues. Point to a given area of your office and ask 2-5 people how clean a given area, such as your desk is. Instead of accepting a single answer, dig in a bit as to why they answered the way they did. Most likely, you will get as many distinct answers as people that you talk to. This exercise illustrates how hard it is to give a good answer to how maintainable software a given piece of software is.
The best way to provide metrics for maintainability is usually with various Static Code Analysis tools. Almost every mature language has at least one tool to do this, and each tool usually measures a fair number of metrics. These metrics will use established (and sometimes experimental) industry practices to look at the source code of your project and determine if there are issues that can be addressed. In addition to those metrics, those same tools often look for “problematic” and “sloppy” code. Problematic code is usually some manner of pattern that a fair number of experts have agreed is a bad thing, such as appending to a string within a loop. Sloppy code is usually things like having a variable or a parameter that is not being used, or a forgotten comment on a public method.
In addition to Static Code Analysis, teams must continue to strive to have a good set of documentation on what the project is doing, and regularly maintain that documentation. While the “correctness” of the documentation is harder to measure than source code, it is pivotal for a project. How much of the information on the various projects that your team supports is in the head of one or two individuals? What is going to happen if they leave the team or leave the company.
Your team should not need volumes of information on every decision that was made, but as a team, it is imperative to document the major decisions that affect the flow of the project. It is also a good idea to have solid documentation on building, deploying, and executing the project. Imagine yourself as a new team member looking at the software project and any documentation, and honestly ask yourself “How much would I want to run away from that project?” If the honest answer from each member of the team is something similar to “I’m good”, you probably have a decent level of documentation.
A Note On Static Code Analysis¶
Before delving deeper into maintainability, I want to take a minute to talk about Static Code Analysis. Typically, Static Code Analysis is used as a gatekeeper for maintainability, and as such, any suggestions should be strictly followed. However, Static Code Analysis tends to be an outlier to the gatekeeper rule in that the metrics need to be “bent” every so often. This “bending” is accomplished using some form of suppression specified by the Analyzer itself.
Static Code Analyzers tend to fall into two main categories: style and correctness.
Any warnings that are generated by a style analyzer should be addressed without fail. In terms of stylistics, there are very few times where deviating from a common style are beneficial, and as such should be avoided. As stylistics can vary from person to person when writing code, it is useful to supplement the style analyzer with an IDE plugin that will reformat the source code to meet the team’s stylistics, with the Static Code Analyzer acting as a backstop in case the IDE formatting fails.
Warnings generated by correctness analyzers are more likely to require bending. Most correctness analyzers are based on rules that are normally correct, but do have exceptions. As such, your team should deal with these exception by having a follow up rule on when it is acceptable to suppress the exceptions, and specifically on a case-by-case basis. It is also acceptable to suppress the exception after generating a future requirement to address the exception, if your team is diligent on following up with these requests.
In both cases, it is important to remember that SCAs are used to help your team keep the project’s maintainability at a healthy level.
Back to Maintainability¶
In the upcoming article Software Quality: Maintainability, I will delve more into breaking
the Maintainability pillar into S.M.A.R.T. requirements and I provide suggestions on how it can
be measured. I will do this by presenting the 4-5 metrics that I consider to be useful as
well as both patterns and anti-patterns to avoid. [ED: Need to rephrase that last sentence.]
Efficiency¶
The essence of this pillar can be broken down into one question:
- Does the software execute that task in a timely manner?
Similar to my analogy of maintainability being the cleanliness of your software, efficiency is whether or not your software is executing “fast enough”. Coming up with an answer to a question on whether or not something is “fast enough” is usually pretty easy. But when you ask for a definition of what “fast enough” means, that is when people start to have issues coming up with a solid answer. In my experience, a large part of the reason for that vagueness is usually not having a good set of requirements.
As an example, let’s figure out what “fast enough” means for two different video games that my family plays: Civilization and Rocket League.
For the game Civilization (in multiplayer mode), the big delays in the game are the human interactions and decisions required before a player ends their turn. It is also very important that all of the information get conveyed between turns so that the multiplayer server can accurately record actions in a fair and just manner. For this game, “fast enough” for the software is largely dwarfed by the delays that the players introduce. However, if we have a game with 12 players, 2 of them human and the other 10 using the game’s AI players, then we can start to formulate what “fast enough” is for the AI players. It really depends on the context.
Rocket League is a different story. Rocket League is a sequel to the game “Supersonic Acrobatic Rocket-Powered Battle-Cars” released in 2008. In this game, you play a game of arena soccer using rocket powered cars, each match consisting of a series of games between teams of 1-3 players. Unless there is a LAN tournament between professional teams, it is very rare for more than one player to be in the immediate vicinity of their teammates, and often players are from different states/provinces and even countries. For the client software on the player’s computers, “fast enough” is measured by latency and packet loss. With each player’s action being relayed to the server and then back out to the other players, any packet loss or increase in latency will impact the server’s reaction to various inputs from the player’s controllers. For this type of game, “fast enough” depends on a good network connection and a server that is able to process many actions per second.
As you can see from the video game example, efficiency greatly depends on what the requirements
of the software are. In the upcoming article Software Quality: Efficiency, I will delve
more into breaking the Efficiency pillar into S.M.A.R.T. requirements and I provide
suggestions on how it can be measured.
Security¶
The essence of this pillar can be broken down into one question:
- How easy is it for a third party to perform malicious actions with your software?
That is one dramatic question. “Perform malicious actions.” Wow! I have read all sorts of articles on various news sites about those, but surely they cannot affect my software? That is usually one of the first reactions of a lot of software developers. Just 10 minutes with a security researcher can open your eyes to what is possible.
To understand this better, pretend that your software project is on a slide, being viewed through a microscope. If you look at the slide without the microscope, you just see your software on the slide, pretty much the same as any other slide. However, if you increase your magnification by one order of magnitude, you see that your project includes your source code and components developed by other people. You may be following proper security practices, but did they?
Another order of magnitude down, and you are looking at the low level instructions for your project and any included components. Once the component was assembled, could a third party have added some malicious code to that component, executing normally until they activate it? Was that malicious code in their from the beginning? Or maybe it is a vulnerability at the source code, machine code, or machine levels? Someone can make a small change to a component to utilize that vulnerability with little effort if they know what they are doing.
Reversing our direction, if we expand outwards instead of inwards, we have containerization. Containerization solutions, such as Docker, provides a complete computing environment to execute your software within. Popular with back end development, you encapsulate your software with it’s intended operating system platform, reducing the number of platform’s you need to design your software for to 1. But with containerization, we also have to ask the same questions of the platform as we did with the software. How secure is the operating system that the container uses as it’s base?
In today’s world of software development, where componentization is key, the software you
write is not the only place where security issues can be introduced. However, there are
proactive steps you can take to reduce the vectors than users can
follow to use your software maliciously.
In the upcoming article Software Quality: Security, I will delve more into breaking
the Security pillar into S.M.A.R.T. requirements and I provide suggestions on how they it
be measured.
Back To Requirements¶
Having explored the 4 pillars, it is important to bring the discussion back to the definition of good requirements. Using the information from each of the individual pillar articles in concert with the information on S.M.A.R.T. terminology, your team can request requirements that are more focused. As any focused requirements will be Specific (the S. in S.M.A.R.T.), it is reasonable to expect that any impact on our 4 pillars will be noted. Asking for this change will almost guarantee some negotiations with the team’s stakeholders.
In my experience, when your team asks for more focused goals from your stakeholders, there will typically be some pushback from those stakeholders at the beginning. If your team has had some requirements mishaps in the past, highlight each mishap and how the ensuing loss of time and focus could have been avoided usually sways stakeholders. Don’t point fingers, but simply point out something like:
Hey, when we did the X requirement, we all had a different idea on what to fix, and as such,it took X hours of meeting and Y hours of coding and testing to figure out it was the wrong thing. We just want to help tune the requirements process a bit to help everyone try and avoid that waste.”
Most stakeholders are being asked to have their teams do the maximum amount of work possible in the shortest amount of time. By asking that question in such simple manner, you are asking if you can spend a small amount of time up front to hopefully eliminate any such missteps. Most stakeholders will grab on to that as a way for them to look good and for the team to look good, a win-win.
What will these requirements look like?¶
The requirements will typically come in two main categories. The first category, requirements focused on fixing bugs or adding features, will typically be the bulk of the requirements. Each requirement should outline any negative impact it will have on any of the metrics. If nothing is added on negative impacts, the assumption is that the impact will be neutral or positive.
A good example of this is a requirement to add a new feature to the project. The requirement should be clearly stated using S.M.A.R.T. terminology, because it will remove any ambiguity in the requirements. As any source code added without tests would impact any reliability metrics, reliability tests should be added to meet any seldom violated metrics for your project. In similar ways for the other 3 pillars, it is assumed that any source code added will be a step forward or neutral in terms of quality, not backward.
At some point in your project, you should expect that at least a few of the requirements will appear in the the second category: requirements specifically targeted at one or more of the pillars. These requirements allow your team to focus on some aspect of your project where your team feels that the quality can be improved. The big caveat with these requirements is to be mindful of the Achievable and Time-Related aspects of S.M.A.R.T. requirements. Make sure that whatever the goal of these requirements are, they are things that won’t go on forever and are not pipe dreams.
A good example of this is wanting to improve the efficiency of your project or processes. Without a good requirements that is Specific, Achievable and Time-Related, this can go on forever. A bad requirement would state something like “Make the project build faster”. A good requirement might state something like “Reduce the unit test time from 20 seconds to under 15 seconds”, timeboxed to 4 hours. The good requirement has good guard rails on it to keep it from exploding on someone who picks up that work.
Publishing Software Quality¶
Having gone through the previous sections and any related articles, you should have a better idea on:
- how to write better requirements to ask for software quality to be improved
- what metrics I recommend to use for each of the four pillars
- how to measure those metrics and integrate them into your projects
Using this information as tools, your team can improve the quality of the project at it’s own pace, be that either an immediate focus or a long term focus for your project.
For any metrics that are in the seldom violated category, the best way to approach them is to make them gatekeeper metrics for your project. It should be possible to execute a great many of the gatekeeper metrics before a commit happens, which is optimal. For the remaining metrics in the seldom violated category and metrics in the the positive momentum category, your team should publish those metrics with every commit or push, giving the submitter that needed feedback.
In addition, publishing the metrics to some kind of data store allows your team to determine how the project quality is trending over time, allowing any stakeholders or project members to observe any potential software quality issues and take steps to deal with them. Even for certain seldom violated metrics, it can be useful to track how they are trending, even if they are trending above the gatekeeper lines set for the project.
If your team does not publish those metrics in some form, the only data point they have for the project is a binary one: it passes or it does not. From my experience, that binary metric is often a false positive that burns teams due to a lack of information.
What Does Software Quality Mean To Me?¶
Software quality means each software project has a plan. When requirements come in to the project, they are detailed using the S.M.A.R.T. terminology. If not specifically geared towards a given software quality pillar, each requirement may specify what kind of impact it has on one or more of the pillars. If not specified, it is assumed that it has a neutral or positive effect on all of the software quality pillars. The goals are also specific, not overly broad, and realistically achieved within a given time frame.
Software quality means that metrics are well thought out for each project. Each metric is both defensible and reasonable for that project and that team. Any metrics that are not being used as gatekeepers are published so they can be tracked over time. For additional benefit, non-binary gatekeeper metrics are also published, to further improve the project and the quality of the project.
Software quality means ensuring that software projects are reliable. Projects have well thought out tests that are performed at many levels to ensure that the project’s components work together to meet the project requirements as well as verify the correctness of the components themselves. These tests are executed frequently, and a large number of them are used as gatekeepers, trying to ensure that only reliable changes are made to the project. When a project is released, the scenario coverage is 100% and the code coverage is either at 100% or whatever percentage the team has negotiated and documented for their project.
Software quality means ensuring that software projects are maintainable. This entails sufficient documentation of project goals, architecture, design, and current state. The documentation is coupled with Static Code Analysis to measure a number of maintainability metrics and to gatekeep on most of them, ensuring that the project moves in a positive direction to a higher quality project.
Software quality means ensuring that software projects and their processes are efficient. Team process to administrate and maintain the software and the software itself do not have to be blindingly fast, but they need to be as efficient as they need to be for that project and for that team. They do not need to be fast as lightning, only fast enough for the software project itself.
Software quality means ensuring that software projects are secure. If third party components are used for the project, those components need to be monitored for vulnerabilities, and any issues that arise must be addressed quickly. Steps are taken, at a level that is appropriate for the type of software project, to reduce the possible ways that an user can use the software project do something malicious.
To me, software quality is about the journey, continuously improving quality and showing that progress, while adding new features and fixing bugs at the same time.
Wrapping It Up¶
To put it succinctly, software quality for a project is about having a common nomenclature describing the various pillars of quality, having a common way of measuring against each of those pillars, and the publishing of those measures.
Therefore, from my point of view, software quality is not a single metric but a collection of metrics and a philosophy. That philosophy is that your team can only really answer that question by having clearly defined goals for your project and it’s quality metrics, and steering the project towards those goals.
Does every project need to be super high quality? No, not even close. But I firmly believe that each project needs to have a solid understanding of what level of software quality they have in order to negotiate the definition of “good enough” for each project.
-
In the United States, where I currently live, I am a Software Development Engineer in Test or SDET. I do not have an engineering degree. In any other country, including my native Canada, I am a Software Developer in Test or SDT. ↩
-
In the United States, where I currently live, a Software Development Engineer or SDE is the same as a Software Developer in any other country. ↩
-
Based on my experience, where the article breaks out
Sizeas it’s own pillar, I would place it in the Maintainability section. Similarly, while I can understand why they placeIndentifying Critical Programming Errorsin its own section, I would most likely fold half of the items into the Maintainability section and half of them into the Reliability section. To be clear, I agree with the content they present, it is just the organization that I disagree with on two small points. ↩
Comments
So what do you think? Did I miss something? Is any part unclear? Leave your comments below.