In the main article titled What is Software Quality?, I took a high level look at what I believe are the 4 pillars of software quality. This article will focus specifically on the Reliability pillar, with suggestions on how to measure Reliability and how to write good requirements for this pillar.
Introduction¶
From the main article on What is Software Quality?, the essence of this pillar can be broken down into two questions:
- Does the software do the task that it is supposed to do?
- Does the software execute that task in a consistent manner?
This article will take an in-depth look at common types of tests, discussing how those tests can help us gather the information necessary to answer those questions. At the end of this article, the section How To Measure Reliability will use that information to provide a cohesive answer to those questions.
How Does Testing Help Measure Reliability?¶
As discussed in the main article’s section on Reliability, many articles on testing and reliability refer to a test pyramid that defines the 4 basic types of reliability tests: unit tests, functional/integration tests, scenario tests, and end-to-end tests. While those articles often have slightly different takes on what the pyramid represents, a general reading of most of those articles leaves me with the opinion that each test in each section of the pyramid must pass every time. With tests and reliability being closely related, it is easy for me to draw the conclusion that if tests must pass every time, then reliability is a binary choice: they all pass and the project is reliable, or one or more fail and the project is not reliable.
As such, my main question is: Does it have to be a binary choice? Are the only two choices that either all tests did pass or all tests did not pass? If the answer to that question is a binary answer, then the answer is simple: it is either 100% reliable or 0% reliable. More likely, there are other answers that will give use a better understanding of how to measure reliability and how to interpret those measurements.
Can We Identify Groups of Tests?¶
Before determining whether or not reliability is a binary choice, I feel that it is important to make some foundational decisions on how to measure reliability based on the types of tests that are already identified. To aid in making those decisions, it helps to examine the four categories of tests, looking for groupings between them.
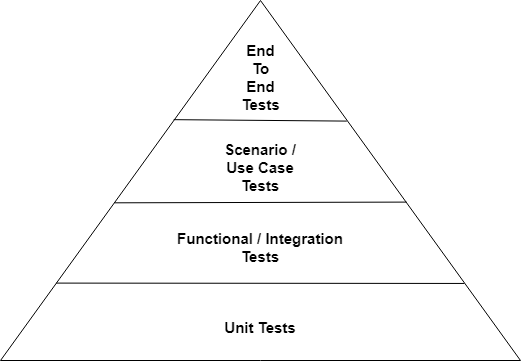
Using the definitions established in the main article, unit tests are used to test the reliability of individual software components and functional tests are used to test the reliability of more than one of those components working together. Both of these categories are used to determine the reliability of the components themselves, and not their objectives. As such, they make for a good grouping as they have a common responsibility: technical reliability.
Observing the scenario tests and end-to-end tests through a similar lens, those tests are used to determine whether or not the software project meets its business requirements. The end-to-end tests are often a set of tests that are very narrow and deep of purpose. At a slightly lower level, the scenario tests provide extra support to those end-to-end tests by breaking those “bulky” end-to-end tests into more discrete actions matched to the overall business use cases for the project. A good grouping for these tests is by what they: business reliability.
Another way to think about it is to view the groups of tests in terms of whether or not they are inside or outside of the black box that is the software project. The first group of tests verify the inside of that black box, ensuring that all of the technical requirements or “what needs to be done to meet expectations” are met. The second group of tests verify the outside of that black box, ensuring that all of the business requirements or “what is expected of the project” are met.
[Add picture of pyramid showing inside and outside?]
Give Me an Example¶
For the follow sections, I use the example of a simple project that uses a data store to keep track of contact information. By providing a simple example that most developers have encountered before, my hope is that it will make it easier for the reader to picture the different types of tests and how they will interact with their team’s project. As I examine each type of tests, I try and explain my thinking on what I write and how I write it for that group of tests, hoping to guide others on making better decisions for their testing strategy.
Note that I do not believe that the definition of “data store” is relevant to the example, therefore the definition of “data store” is left up to the reader’s imagination and experience.
End-To-End Tests¶
Starting at the top of test pyramid, each end-to-end test needs to be a solid, representative test of the main focus of the project itself. These tests are usually a small set of tests meant as a solid litmus test on whether the software project is reliably meeting the requirements of the project. In forming the initial end-to-end tests, my intent is to start with a focus on positive cases which occur more than 60% of the time.
For the example project, I started with a test to successfully add a new contact. As a nice bonus, starting with that test allowed me to add the remove, list, and update end-to-end tests, as they all need to add a new contact as a foundation of each of those 3 individual tests. Given my experience measuring quality, I believe that all of those tests together provide that check with confidence for the example project. If I had found out that the number of end-to-end tests I needed was more than a handful of tests, I would have then examined the requirements and try to determine if the project had too many responsibilities. Doing this exercise with a new project often helps me figure out if the project is properly scoped and designed, or if it requires further refinement.
Having identified the end-to-end tests for a project and assuming that no further refinement is necessary, I rarely write source code for these tests right away. Most of the time I just add some simple documentation to the project outlined in pseudocode to capture that information. I find that the main benefit of doing this in the early stages is to provide a well-defined high level goal that myself and my team can work towards. Even having rough notes on what the test will eventually look like can help the team work towards that goal of a properly reliable project.
Scenario Tests¶
Still on the outside of the box, I then add a number of scenario tests to expand on the scope of each of end-to-end tests. For these tests, I focus on use cases that the user of the project will experience in typical scenarios. The intent here is to identify the scenario tests that collectively satisfy 90% or more of the projected business use cases for a given slice of the project.
For the example project, adding a test to verify that I can successfully add a contact was the first scenario test that I added. I then added a scenario for the negative use case of adding a contact and being told there are invalid fields in my request and a third for a contact name that already existed. Together, these scenarios met my bar for the “add a contact” slice of the scenarios for the project.
It is important to remember that these are tests that are facing the user and systems they interact with. Unless there is a very strong reason to, I try and avoid scenario tests that depend on any specific state of the project unless the test explicitly sets that state up. From my experience, such a dependency on external setup of state is very fragile and hard to maintain. It also raises the question on whether or not it is a realistic or valuable test if that setup is not something that the project itself sets up.
Why only those 3 scenario tests?¶
Here is a simple table on what types of scenario tests to add that I quickly put together for that project. The estimates are just that, examples, but helped me determine if I hit the 90% mark I was aiming for.
| Category | Percentage | Scenario |
|---|---|---|
| Success | 60% | Add a contact successfully to the project. |
| Bad/Invalid Data | 25% | Add an invalid contact name and validate that a ValidateError response is returned. |
| Processing Error | 10% | Add an contact name for an already existing contact and validate that a ProcessingError response is returned. |
I sincerely believe that between those 3 scenario tests, I can easily defend that they represent 90%+ of the expected usage of the project for the specific task of adding a contact. While the percentages in the table are swags that seem to be “plucked out of thing air”, I believe they can be reasonably defended1. This defense only needs to be reasonable enough to get the project going. Once the project is going, real data can be obtained by monitoring and more data-driven percentages can be used, if desired.
How did I get there?¶
From experience, there are typically 4 groups of action results, and therefore, scenarios: the action succeeded, the action failed due to bad data, the action failed due to a processing error, or the action failed due to a system error.
The first scenario test represents the first category. Unless there was a good reason to show another successful “add” use case, I will typically stick with a single “add” test. As the goal is to achieve 90% of the typical use cases for the project, unless a variant of that success case is justified by it’s potential contribution towards the 90% total, it can be better performed by other tests. In addition, tests on variations of the input data are better performed by unit tests and functional tests, where executing those tests have lower setup costs and lower execution costs.
The second scenario test is used to satisfy the second group of tests where the data is found to be bad or invalid. In general, I use these to test that there is consistent error handling 2 on the boundary between the user and the project. At this level, I ideally need only one or two tests to verify that any reporting of bad or invalid data is being done consistently. By leaving the bulk of the invalid testing to unit testing and/or functional testing, I can simulate many error conditions and check them for consistent output at a low execution cost. To be clear, if possible I try and verify the general ability that consistent error handling is in place and not that a specific instance of error is being reported properly.
The third scenario test is used to verify the third group of tests where data is valid but fails during processing. Similar to the second group of tests, there is an assumption that the reporting of processing errors should be done consistently. However, as most processing errors result due to a sequence of actions originating from the user, representative types of processing errors should be tested individually. The key to this type of scenario tests is to represent processing errors that will help the group of scenario tests hit that 90% mark. Relating this to the example project, getting a “already add a record with that name” response from the project is something that would occur with enough frequency to qualify in my books.
From experience, the fourth group of tests, testing for system errors, rarely makes it to the level of a scenario test. In this example, unless a system error is so consistent that it was estimated to occur more than 10% of the time, a higher priority is placed on the other types of responses.
One of the exceptions to these generic rules are when a business requirement exists to provide extra focus on a given portion of the interface. These requirements are often added to a project based on a past event, either in the project or in a related project. As the business owners have taken the time to add the business requirement due to its perceived priority, it should have a scenario test to verify that requirement is met.
In the contact manager example, I made a big assumption that unless there were requirements that stated otherwise, the data store is local and easy to reach. If instead we are talking about a project where the data is being collected on a mobile device and relayed to a server, then a test in this last group of system errors would increase in value. The difference that this context introduces is that it is expected that project will fail to reach the data store on a frequent basis, and hence, providing a scenario for that happening helps us reach that 90% goal.
Commonalities between End-to-end tests and scenario tests¶
While I took the long way around describing end-to-end tests and scenario tests, I believe the journey was worth it. These two types of tests test against the external surface of the project, together painting a solid picture of what that external surface will look like once the project is done. For both of those tests, the project needs clear business requirements on what benefit it provides to the user, which will be highlighted by translating the requirements into the various tests. By including either actual data (for existing projects) or projected data (for new projects) on the usage patterns for that project, the requirements can be prioritized to ensure the most frequently used requirements are more fully tested.
For each of those requirements and goals, the team can then set goals for the project based on those documented requirements. By codifying those goals and requirements with end-to-end and scenario tests, you firm up those goals into something concrete. Those actions allow the team to present a set of tests or test outlines to the authors of the requirements, validating that things are going in the right direction before writing too much source code or setting up of interfaces with the user. That communication and changing the course before writing code can save a team hours, days, or weeks, depending on any course changes discovered.
What happens if the requirements change? The project has a set of tests that explicitly test against the outside of the box, and informs the team on what changes will be needed if that requirement change is applied to the project. At the very least, it starts a conversation with the author of the requirement about what the external surface of the project will look like before and after the change. With that conversation started, the team can have a good understanding of how things will change, with some level of confidence that the change is the change specified by the requirements author.
Unit Tests and Functional Tests¶
Transitioning to inside of the black box, unit tests and functional tests are more understood by developers and more frequently used than end-to-end tests or scenario tests. The unit tests isolate a single component (usually a class) and attempt to test that each interface of that component and is functioning properly. The functional tests do the same thing, but with a single group of components that work together as a single component rather than a single component itself.
From an implementation point of view, the main difference is in how these tests are created. Unit tests, as they are testing a single component, should only contain a project reference to the one component being tested. If the components are created properly and have a good separation from the rest of the project, this should be achievable for a good number of components for the project, especially the support components. Therefore, the degree to which these tests are successful is determined by the amount of clean division of responsibilities the project has between it’s components.
Functional tests complete the rest of the inside-of-the-box testing by testing individual components with related components, in the way they are used in a production environment. With these tests, the degree to which these tests are successful is the ability to inject the project dependencies into one or more of the components being tested, coupled with the clean division of responsibilities needed for good unit tests. While using a concept such as the interface concept from Java and C# is not required, it does allow the injection of dependencies to be performed cleanly and with purpose.
To enable groups of functional tests to be as independent of the components outside of their group as possible, mock objects are often used to replace concrete classes that are part of your project. If interfaces are used in your project to allow for better dependency injection, your functional tests can create mock objects that reside with your tests. This provides more control and reliability on what changes you are making from the live instance of the interfaces, for the sake of testing. If interfaces are not supplied for better dependency injection, a mocking library such as the Java Mockito are required to replace test dependencies with reliable objects.
Back to our example¶
Using the example project as a template, we know from the section on scenario tests that we need to test for valid inputs when adding a new contact. To add coverage for the component containing the “add a contact” logic as a unit test, it’s success is determined by how much of the handling the external interface is in the one component. If that component contains all of the code needed to handle that external request in one method, it is extremely hard to test that component without bringing in the other components. That is definition of a functional test, not a unit test. As an alternative, if the validation of the input can be condensed into it’s own component and removed from that method, that validation component can be unit tested very effectively.
Applying that refactoring pattern a couple of more times in the right ways, the project’s ability to be functionally tested increases. As an added bonus, depending on how the refactoring is accomplished, new unit tests can be added based on the refactoring, gaining measurable confidence on each additional component tested.
Using the adding a contact example again, having refactored the input validation to a validation class could be followed by the following changes:
- create a new component for the handling of “add a contact” and decouple it from logic of the handling of the external interface
- move the user authentication and authorization logic into it’s own component
- move the persisting of the new contact logic into it’s own component
From a functional test point of view, each of these refactorings makes it easier to test. For the first refactoring, instead of having to rely on all functional testing going through the external interface, which may include costly setup, we can create a local instance of the new component and test against that. If interfaces are used for the remaining two refactorings, then test objects can be used instead of the “live” objects, otherwise a mocking library can be used to replace those objects with more predictable objects.
How is each group of Tests Measured?¶
On this winding journey to determine how to measure reliability, I explored the relevant elements of the four main types of tests. I believe that I was successful in showing a clear delineation between the two groups of tests and the benefits each group provides. To recap, the outside-of-the-box group validates the expectations to be met, matched against the requirements set out for the project. The inside-of-the-box group validates how those exceptions are met, matched against the external interfaces for the project.
These two distinct foundations are important, as the two distinct groups of tests require two distinct groups of measurements.
The first group, scenario tests and end-to-end tests, are measured by scenario coverage. Scenario coverage measures the number of tests that successfully pass against the total number of scenario tests and end-to-end tests for that project. As this group of tests is measuring the business expectations of the project, this measurement is a simple fraction: the number of passing tests as the numerator and the number of defined tests as the denominator.
The second group, unit tests and functional tests, are measured by source code coverage, or code coverage for short. Code coverage can be specified along 6 different axes: class, method, line, complexity, blocks, and lines. Different measurement tools will provide different subsets of those measurements, but in the end they are all relaying the same thing: the points in the project’s source code that are not properly tested.
Back to the original question¶
Does it (the measuring of reliability) have to be a binary choice?
It depends.
In an ideal world, the answer to that question is yes, but we do not live in an ideal world. In the real world, we have a decision to make for either group of tests on what is good enough for the project and that group of tests.
If the suggestions of this article are followed, then a condition of releasing the project to a production state is 100% scenario coverage. Anything less than 100% means that critical use cases for the project are not complete, hence the project itself is not complete.
To achieve the 100% coverage without adding new project code, updated requirements are needed from the requirements author, say a project manager, to change the composition of the scenario tests and end-to-end tests. This may include removing some of these tests as the release goals for the project are changed. While changing and removing goals and their tests, may seem like cheating to some people, the other option is very risky.
It should be evident that if a project is released without all scenario tests and end-to-end tests passing, that team is taking a gamble with their reputation and the reputation of the project. It is better to adjust the tests and goals, and communicate those changes, than to take a risk on releasing something before it meets those goals.
Following the suggestions of this article for code coverage is a more nuanced goal, and really does depend on the project and the situation. If architected and designed to support proper testing from the beginning, I would argue that 95%+ code coverage is easy and desirable. If you are adding testing to an already existing project or do not have the full support of the developers on the project, this number is going to be lower.
Another factor is the type of project that is being tested and who will use it. If you are creating this project to support people inside of your company, it is possible that one of the requirements is to have a lower initial code coverage target to allow the project to be used right away and alleviate some internal company pressure. If the project is something that will represent you and your company on the international stage, you will have to balance the time and effort needed to meet a higher bar for code coverage with the need to get the project out where it can be used. As with many things, it is a matter of negotiation and balance between the various requirements.
What Is Really Important¶
I want to stress that I believe that the important thing is that each project measures where they are against whatever goals they set for their project. The team doesn’t need to always maintain a near-100% code coverage measure, but that team needs to know where they stand. This will influence and inform the people that author the requirements and adjust the priorities for the team. Any negotiations within the team can then cite this information and use it to help with the balancing act of adding new features, fixing existing bugs, and enhancing code quality (in this case, increasing code coverage).
How To Measure Reliability¶
To answer the question “Does the software do the task that it is supposed to do?”, scenario coverage is measured. Scenario coverage for end-to-end tests and scenario tests should always be at 100% when a production release of the project is performed. This measurement is binary. Until that release (or next production release) is performed, adding or changing these tests based on the requirements for the next release will inform the team and any stakeholders of how close the team is to satisfying those requirements for that release.
To answer the question “Does the software execute that task in a consistent manner?”, code coverage is measured. Code coverage for unit tests and functional tests should strive for 95% code coverage along all 6 axes with all active tests completing successfully 100% of the time. The test completion percentage must be non-negotiable, but the code coverage percentage must take into account the maturity of the project and the usage of the project. This measurement is non-binary. However, it is important to know your project’s code coverage measurement, and how it trends over time. While the measurement is non-binary, it is suggested to create a binary rule that specifies what the minimum percentage is for each axis, failing the rule if that specific metric falls below the goal percentage.
Wrapping It Up¶
By breaking down the types of tests that are expected for a given project, the two different types of measurements of reliably become more evident. Scenario coverage is determined by outlining the major scenarios for using a project and writing end-to-end tests and scenario tests against them. Scenario coverage must be a binary measurement at release time. Code coverage is determined by using tools to measure which parts of the code are executed when running functional tests and unit tests. Code coverage is a non-binary metric that must have a minimum bar for coverage that is met for the project, and determined on the merits of the project itself.
By using these two measurements, I hope that I have shown that it is possible to provide a way to empirically measure reliability. By having a project be transparent about how it is reaching those measurements and what they are, any team can provide meaningful and understandable measurements of reliability.
-
If asked, I could easily defend the percentages. For the success case, I would assume that half the 60% number will come from first try successes and half the number will come from success that occurred after people fixed errors returned from the other two tests and resubmitted the data. While the other two categories are somewhat guesswork, from my experience validation errors are 2-3 times more common than an “existing contact” processing error. Note that in the absence of real data, these are estimates that do not have to be perfect, just reasonable. ↩
-
In designing any type of project, you should seek to have clear and consistent interfaces between your project and the users of the project. An extension of that statement is that any responses you return to your user should be grouped with related responses and returned in a common data structure or UI element to avoid confusion. ↩
Comments
So what do you think? Did I miss something? Is any part unclear? Leave your comments below.